







In today’s fast-paced and data-driven world, accurately predicting demand is more critical than ever for businesses aiming to stay competitive. Traditional forecasting methods often provide a single-point estimate, which can be useful but falls short in accounting for the inherent uncertainties and variability in real-world data. This is where probabilistic forecasting comes into play, offering a more nuanced and comprehensive approach.
For a deeper understanding of various demand prediction techniques, check out our other blog post on different forecasting approaches: Demand sensing and forecasting: Designing a unified solution for retail and manufacturing use cases.
Probabilistic forecasting involves generating a range of possible future outcomes along with their associated probabilities, rather than just a single predicted value. This method not only provides a central forecast but also quantifies the uncertainty around it. By embracing this approach, businesses can make more informed decisions, optimize their operations, and better manage risks.
- Uncertainty quantification: Traditional point forecasts can be misleading as they don’t capture the full spectrum of possible future outcomes. Probabilistic forecasting provides a complete distribution of potential demand, allowing businesses to understand the range of possibilities and their likelihood. This is crucial for making informed decisions under uncertainty.
- Risk management: By understanding the probability of various demand levels, businesses can better prepare for different scenarios. This helps in developing contingency plans and mitigating risks associated with demand variability, such as stockouts, overstocking, or capacity issues.
- Better decision-making: Probabilistic forecasts equip decision-makers with a comprehensive view of future demand, enhancing their ability to plan and allocate resources efficiently. This leads to more robust strategic planning and operational decisions.
- Inventory optimization: One of the biggest challenges in supply chain management is balancing inventory levels. Probabilistic forecasting helps businesses determine optimal inventory levels by providing insights into the likelihood of demand fluctuations, thus reducing costs associated with overstocking and understocking.
- Financial planning: Accurate demand predictions are essential for reliable revenue and cost projections. Probabilistic forecasts allow businesses to perform sensitivity analyses and develop financial plans that can withstand various demand scenarios, leading to more resilient financial strategies.
- Customer satisfaction: Maintaining product availability is key to meeting customer expectations. Probabilistic forecasting enables businesses to better anticipate demand spikes and dips, ensuring that they can meet customer needs consistently, thereby enhancing customer satisfaction and loyalty.
- Competitive advantage: In competitive markets, the ability to accurately anticipate and respond to demand changes provides a significant edge. Companies that leverage probabilistic forecasting can better align their strategies with market conditions, respond quickly to changes, and capitalize on opportunities.
From inventory management and resource allocation to financial planning and customer satisfaction, the applications of probabilistic forecasting in demand prediction are vast and impactful.
Probabilistic approaches comparison
There are numerous methods available to solve these types of problems, each with its own specific area of implementation, pros and cons:
| Name | Overview | Pros & Cons |
| Bayesian Methods | These methods incorporate prior knowledge along with observed data to update beliefs and quantify uncertainty. Example: Bayesian Structural Time Series (BSTS) Data requirements: – Time series data: Regularly spaced observations over time. – Covariates: Optional external variables that can be included as regressors. – Prior information: Optional but beneficial for informing the model. Example: PyMC Data requirements: – Custom data: Flexible to work with any dataset as long as it can be modeled probabilistically. – Prior information: Required for Bayesian inference. – Time series/Cross-sectional data: Depends on the specific model being implemented. | Advantages: Flexible, incorporates prior information, and provides a full distribution of possible outcomes. Disadvantages: Computationally intensive, and requires expertise in Bayesian statistics. |
| Ensemble Methods | Combines multiple models to improve predictive performance and quantify uncertainty. Example: Bootstrap Aggregating (Bagging) Data requirements: – Large dataset: Sufficiently large to benefit from resampling. – Independent observations: The underlying assumption is that observations are independent. Example: Quantile Regression Forests Data requirements: – Predictors and response variable: Both continuous and categorical predictors can be used. | Advantages: Robust, and often improves accuracy and reliability of forecasts. Disadvantages: Can be complex to implement and interpret, and is computationally expensive. |
| State Space Models | Models that describe the evolution of a system’s state over time, incorporating both observations and hidden states. Example: Kalman Filter Data requirements: – Linear time series data: Suitable for linear Gaussian models. – Observations and control inputs: Required to define state transitions and measurements. – Noise parameters: Assumptions about process and measurement noise. Example: Particle Filter Data requirements: – Non-linear time series data: Suitable for non-linear and non-Gaussian models. – Observations and control inputs: To define state transitions and measurements. | Advantages: Well-suited for handling time series with underlying state changes, and can model various types of noise and dynamics. Disadvantages: Can be complex to implement, especially for non-linear systems. |
| Generalized Additive Models (GAMs) | Flexible models that allow for non-linear relationships between the predictors and the response variable. Example: Prophet Data requirements: – Daily observations: Time series data with daily frequency, though it can handle missing days. – Seasonality indicators: Optional indicators for yearly, weekly, and daily seasonality. – Holiday data: Optional but can improve accuracy for business-related forecasting. | Advantages: Interpretable, handles missing data and outliers well, and is suitable for time series with seasonality and trends. Disadvantages: Less flexible than fully custom Bayesian models, and makes strong assumptions about the data structure. |
| Quantile Regression | Predicts specific quantiles (percentiles) of the response variable distribution, providing a full picture of the potential outcomes. Example: Quantile Regression Data requirements: – Predictors and response variable: Both continuous and categorical predictors can be used. – Sufficient observations: Enough data to estimate different quantiles robustly. | Advantages: Simple to implement, and provides clear quantiles for uncertainty estimates. Disadvantages: Assumes a fixed quantile structure, and may not capture complex dependencies as well as other methods. |
| Deep Learning Approaches | Use neural networks to model complex patterns in data and generate probabilistic forecasts. Example: Bayesian Neural Networks DeepAR Data requirements: – Large dataset: Typically requires a substantial amount of data to train effectively. | Advantages: Can capture complex patterns and interactions in large datasets, and is scalable. Disadvantages: Requires large amounts of data, and can be a “black box” with less interpretability. |
| Gaussian Processes | Models the distribution over possible functions that fit the data. Example: Gaussian Process Regression Data requirements: – Moderate dataset size: Computationally expensive, so best suited for moderate-sized datasets. – Kernel choice: Requires an appropriate choice of kernel function to define the covariance structure. | Advantages: Flexible, provides a natural way to quantify uncertainty, and is good for small datasets. Disadvantages: Computationally expensive for large datasets, and can be complex to implement. |
In this blog post, we will focus specifically on implementing the Bayesian approach solutions for several reasons:
- Comprehensive uncertainty quantification: Bayesian methods provide a full probability distribution of the forecast, allowing for a more nuanced understanding of uncertainty compared to single-point estimates.
- Incorporation of prior knowledge: The ability to include prior information helps improve the accuracy of forecasts, especially when data is scarce or noisy.
- Flexibility: Bayesian models can be tailored to capture complex relationships and hierarchical structures within the data, making them highly adaptable to various forecasting scenarios.
- Robustness: By continually updating beliefs with new data, Bayesian methods offer a robust framework for dynamic and evolving demand prediction.
This blog post delves into the importance of probabilistic forecasting and explores various methods of using the most important factors, such as price and time to implement it. Pricing is one of the most important drivers of e-commerce business success. Price optimization strategies depend on various factors such as macroeconomic influence, market conditions, competitor actions, balance of margin, and input costs. Another important component is customer behavior, which varies depending on seasons and holidays. Time is a crucial factor in achieving accurate demand prediction. In this article, we will discuss various approaches to incorporating time-based factors within the Bayesian framework, which is widely used for demand prediction in price optimization tasks.
The Bayesian forecasting approach uses probabilities to express uncertainty about all unknowns, incorporating both data and prior beliefs about how processes work. This contrasts with frequentist approaches, which rely solely on observed data. This methodology allows us to build predictions for intermittent demand or in situations where historical data is limited, which is common for retail products. The Bayesian method’s ability to combine prior knowledge with available data makes it particularly powerful for dealing with uncertainties in retail and e-commerce contexts.
Given these advantages, Bayesian approaches are often considered the best choice for achieving accurate and reliable probabilistic forecasts, especially in industries where data limitations and fluctuating demand patterns are prevalent.
Probabilistic forecasting tools
Let’s dive into a detailed comparison of popular tools that facilitate Bayesian and other probabilistic modeling techniques. Different libraries offer unique strengths and weaknesses, making them suitable for specific forecasting tasks. Some of the leading probabilistic programming libraries are PyMC, Prophet, Pyro, Orbit, NumPyro, and Stan.
| Tool name | Overview | Pros & Cons |
| PyMC | Probabilistic programming library in Python focused on Bayesian statistical modeling and inference. Suitable use case: Complex hierarchical models, custom probabilistic models, and detailed uncertainty quantification. | Advantages: – Flexibility: Allows for building complex custom models. – Bayesian inference: Comprehensive tools for MCMC and variational inference. – Visualization: Strong support for model diagnostics and posterior visualization. – Integration: Works well with NumPy, SciPy, and pandas. Disadvantages: – Learning curve: Requires understanding of Bayesian statistics. – Performance: MCMC can be slow for large datasets or complex models. – Verbose: More code required for simple models compared to specialized libraries. |
| Prophet | Forecasting tool developed by Facebook designed for time series data with strong seasonal effects and holiday impacts. Suitable use case: Business forecasting, time series data with strong seasonality and holiday effects, quick and interpretable results. | Advantages: – Ease of use: User-friendly with minimal parameter tuning. – Automatic handling: Deals with missing data, outliers, and holidays. – Interpretability: Clear and interpretable model components (trend, seasonality, holidays). Disadvantages: – Limited flexibility: Fixed model structure not suitable for complex custom models. – Assumptions: Makes strong assumptions about seasonality and trends. |
| Pyro | Probabilistic programming library built on PyTorch, designed for deep probabilistic modeling. Suitable use case: Deep probabilistic models, large-scale data, and integration with neural networks. | Advantages: – Flexibility: Supports deep probabilistic models and variational inference. – Integration with PyTorch: Leverages PyTorch’s capabilities for deep learning. – Scalability: Handles large datasets and complex models efficiently. Disadvantages: – Complexity: Requires knowledge of both probabilistic modeling and PyTorch. – Learning curve: Steeper learning curve due to its flexibility and power. |
| Orbit | Open-source package developed by Uber for Bayesian time series forecasting. Suitable use case: Time series forecasting, and business applications needing scalable and specialized tools. | Advantages: – Specialization: Designed specifically for time series forecasting. – Ease of use: High-level interface for common forecasting tasks. – Scalability: Optimized for performance with large datasets. Disadvantages: – Flexibility: Less flexible for custom probabilistic models compared to general-purpose libraries. – Community support: Smaller user community compared to more established libraries. |
| NumPyro | Lightweight probabilistic programming library that leverages JAX for accelerated computations. Suitable use case: High-performance probabilistic modeling, large datasets, and leveraging JAX’s capabilities. | Advantages: – Performance: Very fast due to JAX’s just-in-time compilation and automatic differentiation. – Flexibility: Supports a range of probabilistic models. – Scalability: Efficient handling of large datasets. Disadvantages: – Ecosystem: Less mature ecosystem compared to PyMC or Stan. – Learning curve: Requires familiarity with JAX and probabilistic modeling. |
| Stan | State-of-the-art platform for statistical modeling and high-performance statistical computation. Suitable use case: High-performance Bayesian inference, complex and precise statistical models, and applications requiring rigorous statistical accuracy. | Advantages: – Performance: Highly optimized for Bayesian inference with efficient sampling algorithms. – Flexibility: Supports a wide range of models. Disadvantages: – Complexity: Requires understanding of Stan’s modeling language and Bayesian statistics. – Learning curve: Steeper learning curve compared to more user-friendly libraries. |
Each library has its strengths and is suited for different tasks. Choosing the right tool for probabilistic forecasting can significantly impact the ease of model development, computational efficiency, and accuracy of the results. In this particular blog post, we will use PyMC to illustrate possible solutions. This tool was chosen for its flexibility in building custom probabilistic models, allowing users to define complex hierarchical models, specify priors, construct bespoke likelihood functions, and ability to work with limited data.
Probabilistic solution examples
To best illustrate the Bayesian approach, we’ll examine a demand prediction use case that focuses on time and price as the most crucial factors. There are several ways time can be incorporated into the Bayesian model:
- Special objective function:
- Prophet-like model
- Incorporation to model architecture
- Rolling regression model
- Incorporation of time features
- Incorporation to model hierarchy
We will compare these approaches using a generated dataset representing two years of sales for product X. This dataset was generated to exhibit specific patterns, including seasonality, trends, and price-demand relationships that adhere to the law of demand. This economic principle states that higher prices generally lead to lower demand, while lower prices typically result in higher demand.
To measure model quality we will use common approach metrics: Weighted Absolute Percentage Error (WAPE), Root Mean Square Error (RMSE), and the percentage of data points falling within the 95% Credible Interval (CI) of the posterior prediction.


Special objective function
The choice of objective function for demand prediction can be customized based on data availability and specific requirements of each unique case. When dealing with data that exhibit seasonality and trend patterns, an effective approach is to use a Prophet-like model within the Bayesian framework.
Prophet-like model
This approach uses an objective function that incorporates the linear trend and seasonality component.
Linear trend
The linear trend in this model is presented as a linear function
$trend = at + b,$
where $t$ is a scaled day number.

with pm.Model(check_bounds=False) as linear_trend:
α = pm.Normal("α", mu=0, sigma=0.5)
β = pm.Normal("β", mu=0, sigma=0.5)
σ = pm.HalfNormal("σ", sigma=0.1)
trend = pm.Deterministic("trend", α + β * t)
pm.Normal("likelihood", mu=trend, sigma=σ, observed=y_train)This model won’t capture any seasonal fluctuations of price/demand relationships, but can provide a good linear approximation if trend changes in demand are clear.

As observed, the model prediction captures the downward trend, but fails to account for the width of fluctuation around it.

The linear trend model doesn’t capture any relationship between price and demand, which reduces the prediction quality. The WAPE and RMSE values are relatively high for the given data.
| Model | WAPE | RMSE | Percent of points inside posterior prediction (95% CI) |
| Trend | 0.50 | 10.71 | 95.65 |
Linear trend & price
Price is a crucial factor in demand prediction. To improve model quality, we can incorporate it alongside the linear trend as an additional variable in the linear model.
$y = at +a₁price + b$

with pm.Model(check_bounds=False) as linear_trend_price:
α = pm.Normal("α", mu=0, sigma=0.5)
β = pm.Normal("β", mu=0, sigma=0.5)
β1 = pm.Normal("β1", mu=0, sigma=5)
σ = pm.HalfNormal("σ", sigma=0.1)
trend = pm.Deterministic("trend+price", α + β * t + β1 * x_price)
pm.Normal("likelihood", mu=trend, sigma=σ, observed=y_train)
The results already show significant improvement. While the model’s CI remains narrow and doesn’t capture fluctuations around the average prediction, the overall behavior closely resembles the original data.

The model has begun to capture the downward trend in price/demand relationships. However, due to the linear objective function used, this relationship is represented as linear.
| Model | WAPE | RMSE | Percent of points inside posterior prediction (95% CI) |
| Trend + Price | 0.27 | 5.67 | 93.91 |
Linear trend & seasonality
Linear models capture the trend and price/demand relationships, but fail to account for seasonal fluctuations. Seasonality can be incorporated into the model using transformed day or week numbers and additional sin and cos values to represent cyclical patterns. This is presented as a matrix of Fourier features multiplied by a vector of coefficients
$seasonality = β_0sin_0+β_1cos_0+…+\beta_{n*2-1}sin_n+β_{n*2}cos_n,$
where $n$ is number of orders
The number of orders is a hyperparameter that should be tuned to a particular time series. It is the number of sin and cos features added to the dataset to represent the seasonality wave. For example, if n_orders=3, three sin and three cos will be added. The first sin and cos terms represent the transformed week number. A higher n value results in more frequent changes in curve direction.

The objective function incorporating both trend and seasonality factors is as follows:
$y = trend * (1 + seasonality)$

coords = {"fourier_features": np.arange(2 * n_order)}
with pm.Model(check_bounds=False, coords=coords) as linear_with_seasonality:
α = pm.Normal("α", mu=0, sigma=0.5)
β = pm.Normal("β", mu=0, sigma=0.5)
σ = pm.HalfNormal("σ", sigma=0.1)
trend = pm.Deterministic("trend", α + β * t )
β_fourier = pm.Normal("β_fourier", mu=0, sigma=0.1, dims="fourier_features")
seasonality = pm.Deterministic(
"seasonality", pm.math.dot(β_fourier, fourier_features.to_numpy().T)
)
μ = trend * (1 + seasonality)
pm.Normal("likelihood", mu=μ, sigma=σ, observed=y_train)
The model now captures seasonal fluctuations well. The model’s CI has widened, including more data points in the prediction.

This model doesn’t account for price, so the price/demand relationship isn’t well represented. The model prediction appears more like a horizontal line, failing to capture the downward trend.
| Model | WAPE | RMSE | Percent of points inside posterior prediction (95% CI) |
| Trend + Seasonality | 0.27 | 5.64 | 95.65 |
Linear trend & seasonality & price
Let’s add price to improve the model quality. We can incorporate it into the linear trend part of the objective function. The final function will be:
$y = (a_0t + a_1price + b) * (1 + seasonality)$

coords = {"fourier_features": np.arange(2 * n_order)}
with pm.Model(check_bounds=False, coords=coords) as linear_with_seasonality:
α = pm.Normal("α", mu=0, sigma=0.5)
β = pm.Normal("β", mu=0, sigma=0.5)
β1 = pm.Normal("β1", mu=0, sigma=0.5)
σ = pm.HalfNormal("σ", sigma=0.1)
trend = pm.Deterministic("trend", α + β * t + β1 * x_price)
β_fourier = pm.Normal("β_fourier", mu=0, sigma=0.1, dims="fourier_features")
seasonality = pm.Deterministic(
"seasonality", pm.math.dot(β_fourier, fourier_features.to_numpy().T)
)
μ = trend * (1 + seasonality)
pm.Normal("likelihood", mu=μ, sigma=σ, observed=y_train)
linear_with_seasonality_prior_predictive = pm.sample_prior_predictive()
The model now captures fluctuations more accurately. It appears that the highest and lowest points are related to price sensitivity rather than seasonality, which explains why the previous model didn’t capture them.

As we can see on the plot, the downward price/demand relationship is now clearly visible. The shape is closer to exponential, which aligns with the expected price/demand curve.
| Model | WAPE | RMSE | Percent of points inside posterior prediction (95% CI) |
| Trend + Seasonality + Price | 0.27 | 5.64 | 96.52 |
This approach allows consideration of time changes and price, with the potential to add some other features. However, it’s important to remember that adding too many parameters significantly increases the complexity and computational time.
Advantages of approach:
- Considering trend and seasonality significantly improves model accuracy
- Works well for products with clear seasonality
Disadvantages of approach:
- Assumes linear dependency between price and demand, which may not always be accurate
- Time effect is stronger than price effect
- Difficult to isolate price effect
- Difficult to implement additional features or hierarchy
- High n_orders increase computational time
In general, this approach is effective for demand prediction based on time and is suitable for products with low price fluctuation and clear seasonality.
Incorporation into model architecture
Rolling regression
When we train a linear model, we find parameters that are stable. Time is a parameter that changes itself. We assume that the same fixed values for slope and intercept work well for all observations. As time progresses, the dependency between inputs and outputs of the data can change, meaning that the model and its parameters have to change over time as well.
The main idea is not to estimate the coefficients of different data points as independent from nearest points. For example, the coefficient of x of data point 2 should not be far away from the coefficient of x of data point 1. A way to express this is by modeling:
$a(t+1) \sim N(a(t), \sigma ^2)$
for some standard deviation σ for all times t, with some initial value for the first slope like $a(0) = 0$.
$a_t \sim N(a_{t-1}, \sigma ^2 _a)$
$\beta_t \sim N(\beta_{t-1},\sigma ^2 _\beta)$
$\sigma ^2 _a$ and $\sigma ^2 _\beta$ can be interpreted as the volatility in the regression coefficients.
The new time point coefficient slope is the previous one plus some error (Gaussian Random Walk).

with pm.Model() as model_randomwalk:
# std of random walk
sigma_alpha = pm.Exponential("sigma_alpha", 50.0)
sigma_beta = pm.Exponential("sigma_beta", 50.0)
alpha = pm.GaussianRandomWalk("alpha", sigma=sigma_alpha, shape=len(x_price))
beta = pm.GaussianRandomWalk("beta", sigma=sigma_beta, shape=len(x_price))
# Define regression
demand = alpha + beta * x_price
# Assume prices are Normally distributed, the mean comes from the regression.
sd = pm.HalfNormal("sd", sigma=0.1)
likelihood = pm.Normal("y", mu=demand, sigma=sd, observed=y_train)
| Model | WAPE | RMSE | Percent of points inside posterior prediction (95% CI) |
| Rolling regression | 0.22 | 4.81 | 99.13 |
The metrics indicate that this model’s quality is much better than previous versions. However, there are substantial drawbacks to this approach. Computational time and complexity increased significantly, making it impossible to prepare visual representations locally using model results.
Advantages of approach:
- Separate regression parameters are selected for each time point, with closer points having more similar parameters. This means points nearest to the prediction period have a greater influence on the prediction
- The objective function can be any necessary form (linear, sigmoid, exponential, etc.)
- Additional features can be added to the objective function
Disadvantages of approach:
- Computational time increases significantly depending on the number of time periods used for training
Incorporation of time features
When additional features are present or a non-linear objective function is assumed, time can be integrated into any desired model.
Time features can be implemented into the existing model using several techniques:
- One-hot encoding (OHE): Separate feature values are used. Nearby weeks are not considered close in time.
- Ordinal features: Week 1 is considered close to week 2, while week 53 is the most distant.
- Geometric representation: Time periods are represented as a cycle, with points on a circle. December is close to January (same winter season), while winter is most distant from summer, and spring from autumn.

We recommend the third approach. Instead of OHE or week numbers, two additional features can be added: sin(week) and cos(week), representing seasonal changes.
These sin and cos features can be added to the objective function with additional parameter distributions.
$y = (a_0price + a_1sin(t) +a_2cos(t) + b),$
where t is the relevant time period

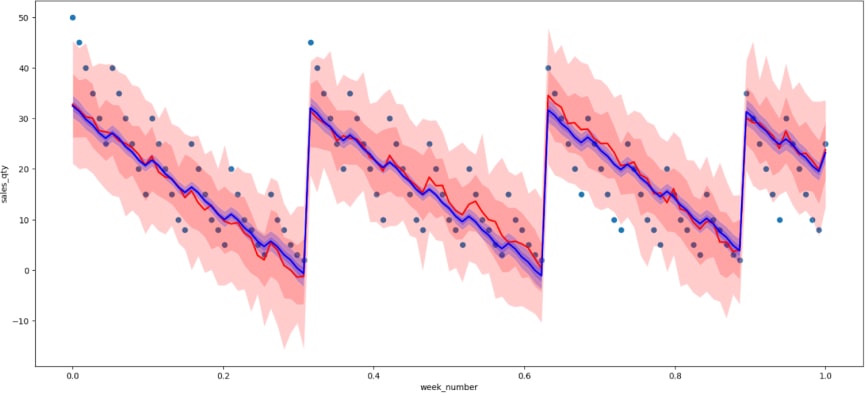
As evident from the plot above, adding time as sin and cos functions instead of a single t parameter to the linear model significantly improves prediction quality. Model predictions now begin to mimic the cyclic behavior of the data.
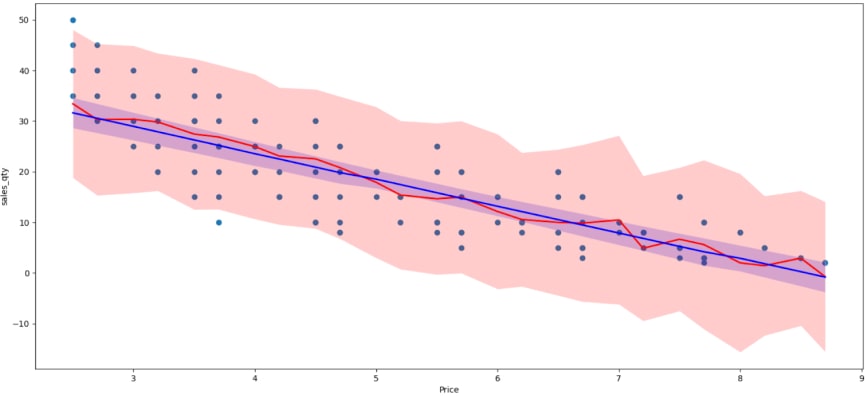
The price/demand relationship is also captured, due to the inclusion of a price feature in the model.
| Model | WAPE | RMSE | Percent of points inside posterior prediction (95% CI) |
| Adding sin and cos features | 0.29 | 6.43 | 92.17 |
Model quality is not optimal and can be improved by using a different objective function instead of linear.
Advantages of approach:
- Time is taken into account in the model
- Objective function can be any necessary form (linear, sigmoid, exponential, etc.)
- Additional features can be added to the objective function
Disadvantages of approach:
- If the model is trained on multiple products, seasonality effects may be diluted due to different product behaviors across time
Incorporation into model hierarchy
The approach we ultimately chose for specific cases was to add product/week pairs to the model hierarchy.
Price-demand relationships can be described with different shapes based on assumptions about their behavior. Most commonly, they are described as linear, exponential, or sigmoid relationships.
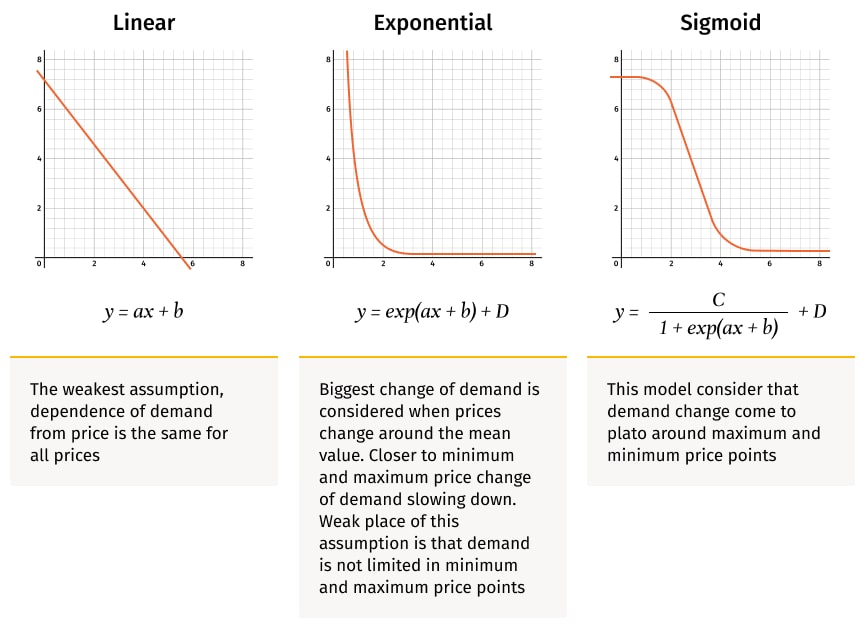
with pm.Model(check_bounds=False) as linear_trend:
a = pm.Normal("a", mu=0, sigma=0.5)
b = pm.Normal("b", mu=0, sigma=0.5)
c = pm.Normal("c", mu=0, sigma=0.5)
d = pm.Normal("d", mu=0, sigma=0.5)
sin = pm.Normal("sin", mu=0, sigma=0.5)
cos = pm.Normal("cos", mu=0, sigma=0.5)
f = (c/(1 + pm.math.exp(a * x_data + b )) + d + sin * day_sin_data + cos * day_cos_data)
pm.Deterministic("model_target", f, dims="obs")
pm.HalfNormal("sig", sigma=0.05)
pm.Normal("likelihood", mu=model_target, sigma=sig, dims="obs", observed=observed)
Any of these models can be used for modeling. We’ll base it on the sigmoid shape of the price/demand relationship because it seems more realistic. Week number can be added to any part of the equation or to all parts. To avoid overfitting, the prod/week prior was added only to the D parameter of the model. This keeps the sigmoid curve shape consistent across weeks, determined by other factors (for example, store type, promotions, etc.), while week number only influences the position of this curve along the Y axis.
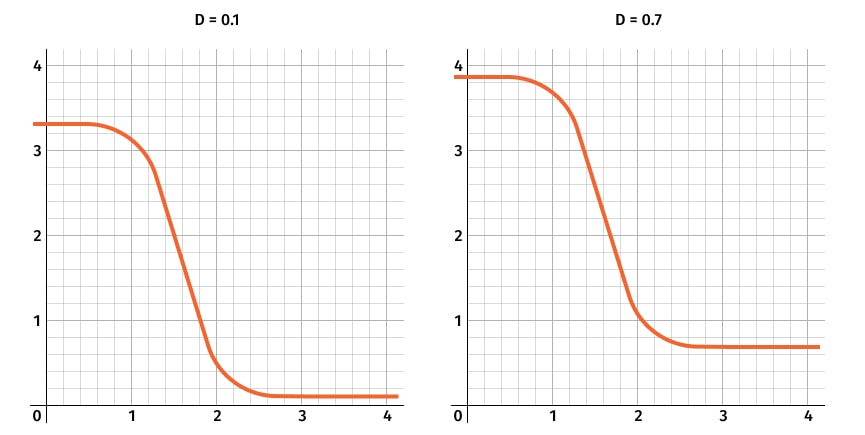
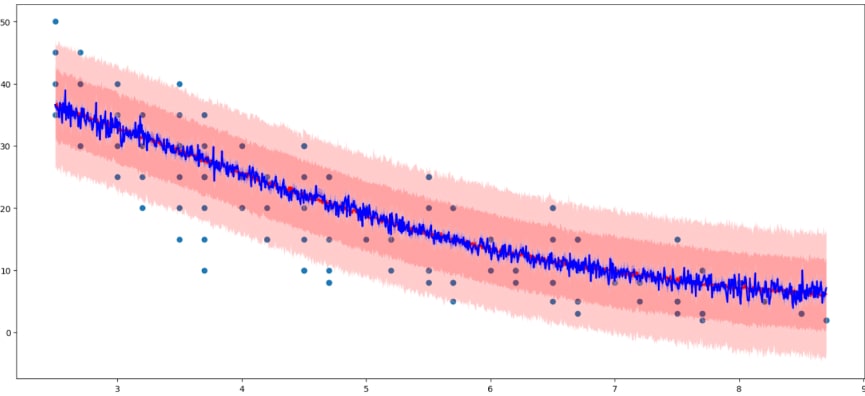
Price/demand relationships are well-captured by the model.
| Model | WAPE | RMSE | Percent of points inside posterior prediction (95% CI) |
| Incorporation time feature to more complex model structure | 0.27 | 5.92 | 92.22 |
For this particular generated dataset, this approach ranks in the top 3 by metric values. In one case resolved by Grid Dynamics for a client, model accuracy improved by 22.9% compared to the baseline without product/week pair in the hierarchy.
Summary
Let’s compare model prediction results to pick the best option:
| Model | WAPE | RMSE | Percent of points inside posterior prediction (95% CI) |
| Trend | 0.50 | 10.71 | 95.65 |
| Trend + Price | 0.27 | 5.67 | 93.91 |
| Trend + Seasonality | 0.27 | 5.64 | 95.65 |
| Adding sin and cos features | 0.29 | 6.43 | 92.17 |
| Trend + Seasonality + Price | 0.27 | 5.64 | 96.52 |
| Rolling regression | 0.22 | 4.81 | 99.13 |
| Incorporation time feature to more complex model structure | 0.27 | 5.92 | 92.22 |
For this generated data, the top 3 approaches are:
- Rolling regression
- Trend + Seasonality + Price
- Incorporating time features into a more complex model structure
Selecting the best approach involves balancing model complexity, and quality with scalability and computational requirements. The optimal choice depends on the specific needs and constraints of the project.
Final words
Probabilistic forecasting provides a more nuanced and informative view of future demand compared to traditional point forecasts. By incorporating uncertainty into the forecasting process, businesses can make better-informed decisions, optimize operations, and enhance overall resilience and responsiveness to market dynamics. In each particular case, the unique needs and capabilities of specific tools should be considered. With the right approach and tools, you can transform your demand prediction processes, making them more resilient and adaptive to the uncertainties of the future.
You might also like








